哈希 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 *target* 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
提示:
2 <= nums.length <= 104
109 <= nums[i] <= 109
109 <= target <= 109
只会存在一个有效答案
示例 :
1 2 3 4 5 6 7 输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 输入:nums = [3,2,4], target = 6 输出:[1,2] 解释:因为 nums[1] + nums[2] == 6 , 返回[1, 2]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public int [] twoSum(int [] nums, int target) { Map<Integer, Integer> map = new HashMap <>(); for (int i = 0 ; i < nums.length; i++) { int num = nums[i]; if (map.containsKey(target - num)) { return new int [] {map.get(target - num), i}; } map.put(num, i); } return new int [] {0 ,0 }; }
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
提示:
1 <= strs.length <= 104
0 <= strs[i].length <= 100
strs[i] 仅包含小写字母
提示:
1 2 3 4 5 6 7 8 输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"] 输出: [["bat"],["nat","tan"],["ate","eat","tea"]] 输入: strs = [""] 输出: [[""]] 输入: strs = ["a"] 输出: [["a"]]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public List<List<String>> groupAnagrams (String[] strs) { Map<Integer, List<String>> map = new HashMap <>(); for (String str : strs) { char [] chars = str.toCharArray(); Arrays.sort(chars); int key = new String (chars).hashCode(); List<String> orDefault = map.getOrDefault(key, new ArrayList <>()); if (orDefault.isEmpty()) { map.put(key, orDefault); } orDefault.add(str); } return new ArrayList <>(map.values()); } public List<List<String>> groupAnagrams (String[] strs) { Map<String, List<String>> map = new HashMap <String, List<String>>(); for (String str : strs) { int [] counts = new int [26 ]; int length = str.length(); for (int i = 0 ; i < length; i++) { counts[str.charAt(i) - 'a' ]++; } StringBuffer sb = new StringBuffer (); for (int i = 0 ; i < 26 ; i++) { if (counts[i] != 0 ) { sb.append((char ) ('a' + i)); sb.append(counts[i]); } } String key = sb.toString(); List<String> list = map.getOrDefault(key, new ArrayList <String>()); list.add(str); map.put(key, list); } return new ArrayList <List<String>>(map.values()); }
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) **的算法解决此问题
提示:
0 <= nums.length <= 105
109 <= nums[i] <= 109
示例:
1 2 3 4 5 6 7 8 9 输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。 输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9 输入:nums = [1,0,1,2] 输出:3
代码:
1 2 3 4 5 6 7 8 9 10 11 public int longestConsecutive (int [] nums) { Arrays.sort(nums); Map<Integer, Integer> map = new HashMap <>(); int r = 0 ; for (int num : nums) { int i1 = map.getOrDefault(num - 1 , 0 ) + 1 ; r = Math.max(r, i1); map.put(num, i1); } return r; }
位运算 给你一个 正 整数 n 。
用 even 表示在 n 的二进制形式(下标从 0 开始)中值为 1 的偶数下标的个数。
用 odd 表示在 n 的二进制形式(下标从 0 开始)中值为 1 的奇数下标的个数。
请注意,在数字的二进制表示中,位下标的顺序 从右到左 。
返回整数数组 **answer **,其中 **answer = [even, odd]
提示:
1 <= n <= 1000
示例:
1 2 3 4 5 6 7 8 9 10 11 输入:n = 50 输出:[1,2] 解释: 50 的二进制表示是 110010。 在下标 1,4,5 对应的值为 1。 输入:n = 2 输出:[0,1] 解释: 2 的二进制表示是 10。 只有下标 1 对应的值为 1。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public int [] evenOddBit(int n) { int [] res = new int [2 ]; int i = 0 ; while (n > 0 ) { res[i] += n & 1 ; n >>= 1 ; i ^= 1 ; } return res; }
双指针 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序(原数组的顺序)。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
**进阶:**你能尽量减少完成的操作次数吗?
提示:
1 <= nums.length <= 104
231 <= nums[i] <= 231 - 1
示例:
1 2 3 4 5 输入: nums = [0,1,0,3,12] 输出: [1,3,12,0,0] 输入: nums = [0] 输出: [0]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public void moveZeroes (int [] nums) { if (nums == null ) { return ; } int j = 0 ; for (int i = 0 ; i < nums.length; ++i) { if (nums[i] != 0 ) { nums[j++] = nums[i]; } } for (int i = j; i < nums.length; ++i) { nums[i] = 0 ; } } public void moveZeroes (int [] nums) { int l, r = 0 ; for (l = 0 ; l < nums.length; l++) { if (nums[l] != 0 ) { swap(nums, l, r); r++; } } } public void swap (int [] nums, int l, int r) { int temp = nums[l]; nums[l] = nums[r]; nums[r] = temp; }
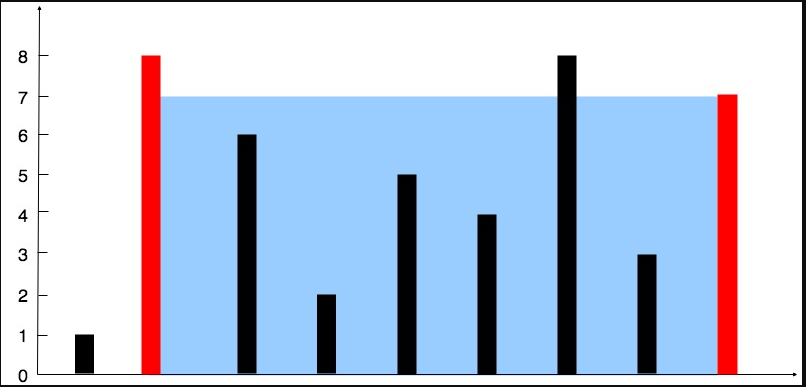
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
**说明:**你不能倾斜容器。
提示:
n == height.length
2 <= n <= 105
0 <= height[i] <= 104
示例:
1 2 3 4 5 6 7 输入:[1,8,6,2,5,4,8,3,7] 输出:49 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下, 容器能够容纳水(表示为蓝色部分)的最大值为 49。 输入:height = [1,1] 输出:1
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public int maxArea (int [] height) { int max = 0 , l = 0 , r = height.length - 1 ; while (l < r) { int area = Math.min(height[l], height[r]) * (r - l); max = Math.max(max, area); if (height[l] < height[r]) { l++; } else { r--; } } return max; }
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
提示:
3 <= nums.length <= 3000
105 <= nums[i] <= 105
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]] 解释: nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。 nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。 nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。 不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。 注意,输出的顺序和三元组的顺序并不重要。 输入:nums = [0,1,1] 输出:[] 解释:唯一可能的三元组和不为 0 。 输入:nums = [0,0,0] 输出:[[0,0,0]] 解释:唯一可能的三元组和为 0 。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 public List<List<Integer>> threeSum (int [] nums) { Arrays.sort(nums); Map<String, List<Integer>> map = new HashMap <>(); int l, r, k = nums.length - 1 ; while (k > 1 ) { r = k - 1 ; l = 0 ; while (l < r) { int i = nums[l] + nums[r] + nums[k]; if (i == 0 ) { String key = String.valueOf(nums[l]) + nums[r] + nums[k]; if (!map.containsKey(key)) { map.put(key, Arrays.asList(nums[l], nums[r], nums[k])); } r--; l++; } else if (i > 0 ) { r--; } else { l++; } } k--; } return new ArrayList <>(map.values()); } public List<List<Integer>> threeSum (int [] nums) { Arrays.sort(nums); List<List<Integer>> res = new ArrayList <>(); for (int i = 0 ; i < nums.length; i++) { if (i > 0 && nums[i] == nums[i - 1 ]) { continue ; } int l = i + 1 , r = nums.length - 1 ; int target = -nums[i]; while (l < r) { int sum = nums[l] + nums[r]; if (sum == target) { res.add(Arrays.asList(nums[i], nums[l], nums[r])); l++; r--; while (l < r && nums[l] == nums[l - 1 ]) { l++; } while (l < r && nums[r] == nums[r + 1 ]) { r--; } } else if (sum < target) { l++; } else { r--; } } } return res; }
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。提示:
n == height.length
1 <= n <= 2 * 104
0 <= height[i] <= 105
示例:
1 2 3 4 5 6 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 输入:height = [4,2,0,3,2,5] 输出:9
代码:解法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public int trap (int [] height) { int n = height.length; int res = 0 ; int left = 0 , right = n - 1 ; int leftMax = height[left], rightMax = height[right]; left++; right--; while (left <= right){ leftMax = Math.max(leftMax, height[left]); rightMax = Math.max(rightMax, height[right]); if (leftMax < rightMax){ res += leftMax - height[left]; left++; }else { res += rightMax - height[right]; right--; } } return res; }
滑动窗口 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
提示:
0 <= s.length <= 5 * 104
s 由英文字母、数字、符号和空格组成
示例:
1 2 3 4 5 6 7 8 9 10 11 12 输入: s = "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 输入: s = "bbbbb" 输出: 1 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。 输入: s = "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public int lengthOfLongestSubstring (String s) { char [] charArray = s.toCharArray(); int res = 0 ; Set<Character> set = new HashSet <>(); for (int i = 0 , j = 0 ; j < charArray.length; j++) { char c = charArray[j]; while (set.contains(c)) { set.remove(charArray[i]); i++; } set.add(c); res = Math.max(res, j - i + 1 ); } return res; }
给定两个字符串 s 和 p,找到 s ****中所有 p ****的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。提示:
1 <= s.length, p.length <= 3 * 104
s 和 p 仅包含小写字母
示例:
1 2 3 4 5 6 7 8 9 10 11 12 输入: s = "cbaebabacd", p = "abc" 输出: [0,6] 解释: 起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。 起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。 输入: s = "abab", p = "ab" 输出: [0,1,2] 解释: 起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。 起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。 起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public List<Integer> findAnagrams (String s, String p) { List<Integer> ans = new ArrayList <Integer>(); int slen = s.length(); int plen = p.length(); if (slen<plen){ return new ArrayList <Integer>(); } int [] count = new int [26 ]; for (int i=0 ;i<plen;i++){ count[s.charAt(i)-'a' ]++; count[p.charAt(i)-'a' ]--; } int differ=0 ; for (int j=0 ;j<26 ;j++){ if (count[j]!=0 ){ differ++; } } if (differ==0 ){ ans.add(0 ); } for (int i=0 ;i<slen-plen;i++){ count[s.charAt(i)-'a' ]--; if (count[s.charAt(i)-'a' ]==0 ){ differ--; }else if (count[s.charAt(i)-'a' ]==-1 ){ differ++; } count[s.charAt(i+plen)-'a' ]++; if (count[s.charAt(i+plen)-'a' ]==0 ){ differ--; } else if (count[s.charAt(i+plen)-'a' ]==1 ){ differ++; } if (differ==0 ){ ans.add(i+1 ); } } return ans; }
子串 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 *该数组中和为 k ***的子数组的个数 。
子数组是数组中元素的连续非空序列。
提示:
1 <= nums.length <= 2 * 104
1000 <= nums[i] <= 1000
107 <= k <= 107
示例:
1 2 3 4 5 输入:nums = [1,1,1], k = 2 输出:2 输入:nums = [1,2,3], k = 3 输出:2
代码 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public int subarraySum (int [] nums, int k) { Map<Integer,Integer> map=new HashMap <>(); int count=0 ; map.put(0 ,1 ); int pre_sum=0 ; for (int i=0 ;i<nums.length;++i){ pre_sum+=nums[i]; if (map.containsKey(pre_sum-k)){ count+=map.get(pre_sum-k); } map.put(pre_sum,map.getOrDefault(pre_sum,0 )+1 ); } return count; }
给你一个整数数组 nums,有一个大小为 k **的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
提示:
1 <= nums.length <= 105
104 <= nums[i] <= 104
1 <= k <= nums.length
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7 输入:nums = [1], k = 1 输出:[1]
代码:
解法说明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public int [] maxSlidingWindow(int [] nums, int k) { int n = nums.length; int [] suffixMax = new int [n]; int [] prefixMax = new int [n]; for (int i = 0 ; i < n; i++) { if (i % k == 0 ) { suffixMax[i] = nums[i]; } else { suffixMax[i] = Math.max(suffixMax[i - 1 ], nums[i]); } } for (int i = n - 1 ; i >= 0 ; i--) { if (i == n - 1 || (i + k) % k == 0 ) { prefixMax[i] = nums[i]; } else { prefixMax[i] = Math.max(prefixMax[i + 1 ], nums[i]); } } int [] ans = new int [n - k + 1 ]; for (int i = 0 ; i < n - k + 1 ; i++) { ans[i] = Math.max(suffixMax[i + k - 1 ], prefixMax[i]); } return ans; }
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
**进阶:**你能设计一个在 o(m+n) 时间内解决此问题的算法吗?
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。
提示:
m == s.length
n == t.length
1 <= m, n <= 105
s 和 t 由英文字母组成
示例:
1 2 3 4 5 6 7 8 9 10 11 12 输入:s = "ADOBECODEBANC", t = "ABC" 输出:"BANC" 解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 输入:s = "a", t = "a" 输出:"a" 解释:整个字符串 s 是最小覆盖子串。 输入: s = "a", t = "aa" 输出: "" 解释: t 中两个字符 'a' 均应包含在 s 的子串中, 因此没有符合条件的子字符串,返回空字符串。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public String minWindow (String s, String t) { int [] map = new int [58 ]; for (char c : t.toCharArray()) { map[c - 'A' ]++; } int left = 0 , right = 0 ; int minLen = Integer.MAX_VALUE; int minLeft = 0 ; int count = t.length(); while (right < s.length()) { char c = s.charAt(right); if (map[c - 'A' ] > 0 ) { count--; } map[c - 'A' ]--; while (count == 0 ) { if (right - left + 1 < minLen) { minLen = right - left + 1 ; minLeft = left; } char leftChar = s.charAt(left); map[leftChar - 'A' ]++; if (map[leftChar - 'A' ] > 0 ) { count++; } left++; } right++; } return minLen == Integer.MAX_VALUE ? "" : s.substring(minLeft, minLeft + minLen); }
普通数组 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
**进阶:**如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的 分治法 求解。
提示:
1 <= nums.length <= 105
104 <= nums[i] <= 104
示例:
1 2 3 4 5 6 7 8 9 输入:nums = [-2,1,-3,4,-1,2,1,-5,4] 输出:6 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。 输入:nums = [1] 输出:1 输入:nums = [5,4,-1,7,8] 输出:23
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public int maxSubArray (int [] nums) { int ans = Integer.MIN_VALUE; int sum = 0 ; for (int num : nums) { if (sum <= 0 ) { sum = num; } else { sum += num; } ans = Math.max(ans, sum); } return ans; }
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
提示:
1 <= intervals.length <= 104
intervals[i].length == 2
0 <= starti <= endi <= 104
示例:
1 2 3 4 5 6 7 输入:intervals = [[1,3],[2,6],[8,10],[15,18]] 输出:[[1,6],[8,10],[15,18]] 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6]. 输入:intervals = [[1,4],[4,5]] 输出:[[1,5]] 解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public int [][] merge(int [][] intervals) { List<int []> list = new ArrayList <>(); PriorityQueue<int []> pq = new PriorityQueue <>((a, b) -> a[0 ] != b[0 ] ? a[0 ] - b[0 ] : a[1 ] - b[1 ]); pq.addAll(Arrays.asList(intervals)); while (!pq.isEmpty()) { int [] cur = pq.poll(); int [] res = new int [2 ]; res[0 ] = cur[0 ]; res[1 ] = cur[1 ]; list.add(res); while (!pq.isEmpty()) { int [] peek = pq.peek(); if (cur[1 ] >= peek[0 ] || res[1 ] >= peek[0 ]) { res[0 ] = Math.min(peek[0 ], res[0 ]); res[1 ] = Math.max(pq.poll()[1 ], res[1 ]); } else { break ; } } } return list.toArray(new int [list.size()][]); } public int [][] merge(int [][] intervals) { if (intervals.length == 0 ) { return new int [0 ][2 ]; } Arrays.sort(intervals, new Comparator <int []>() { public int compare (int [] interval1, int [] interval2) { return interval1[0 ] - interval2[0 ]; } }); List<int []> merged = new ArrayList <int []>(); for (int i = 0 ; i < intervals.length; ++i) { int L = intervals[i][0 ], R = intervals[i][1 ]; if (merged.size() == 0 || merged.get(merged.size() - 1 )[1 ] < L) { merged.add(new int []{L, R}); } else { merged.get(merged.size() - 1 )[1 ] = Math.max(merged.get(merged.size() - 1 )[1 ], R); } } return merged.toArray(new int [merged.size()][]); }
给定一个整数数组 nums,将数组中的元素向右轮转 k **个位置,其中 k **是非负数。
尽可能想出更多的解决方案,至少有 三种 不同的方法可以解决这个问题。
你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
提示:
1 <= nums.length <= 105
231 <= nums[i] <= 231 - 1
0 <= k <= 105
示例:
1 2 3 4 5 6 7 8 9 10 11 12 输入: nums = [1,2,3,4,5,6,7], k = 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: [5,6,7,1,2,3,4] 输入:nums = [-1,-100,3,99], k = 2 输出:[3,99,-1,-100] 解释: 向右轮转 1 步: [99,-1,-100,3] 向右轮转 2 步: [3,99,-1,-100]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public void rotate (int [] nums, int k) { k %=nums.length; reverse(nums, 0 , nums.length - 1 ); reverse(nums, 0 , k - 1 ); reverse(nums, k, nums.length - 1 ); } public void reverse (int [] nums, int start, int end) { while (start < end) { int temp = nums[start]; nums[start] = nums[end]; nums[end] = temp; start += 1 ; end -= 1 ; } }
【数组】、【前缀和】
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 **不要使用除法,**且在 O(n) 时间复杂度内完成此题。
**进阶:**你可以在 O(1) 的额外空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组 不被视为 额外空间。)
提示:
2 <= nums.length <= 105
30 <= nums[i] <= 30
输入 保证 数组 answer[i] 在 32 位 整数范围内
示例:
1 2 3 4 5 输入: nums = [1,2,3,4] 输出: [24,12,8,6] 输入: nums = [-1,1,0,-3,3] 输出: [0,0,9,0,0]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public int [] productExceptSelf(int [] nums) { int [] res = new int [nums.length]; Arrays.fill(res, 1 ); int left = 1 ; int right = 1 ; for (int i = 0 ; i < nums.length; i++) { res[i] = res[i] * left; left = left * nums[i]; } for (int i = nums.length - 1 ; i >= 0 ; i--) { res[i] = res[i] * right; right = right * nums[i]; } return res; }
【数组】,【哈希】
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为O(n)并且只使用常数级别额外空间的解决方案。
提示:
1 <= nums.length <= 105
231 <= nums[i] <= 231 - 1
示例:
1 2 3 4 5 6 7 8 9 10 11 输入:nums = [1,2,0] 输出:3 解释:范围 [1,2] 中的数字都在数组中。 输入:nums = [3,4,-1,1] 输出:2 解释:1 在数组中,但 2 没有。 输入:nums = [7,8,9,11,12] 输出:1 解释:最小的正数 1 没有出现。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public int firstMissingPositive (int [] nums) { for (int i = 0 ; i < nums.length; i++) { if (nums[i] <= 0 ) { nums[i] = nums.length + 1 ; } } for (int i = 0 ; i < nums.length; i++) { int num = Math.abs(nums[i]); if (num <= nums.length) { nums[num - 1 ] = -Math.abs(nums[num - 1 ]); } } for (int i = 0 ; i < nums.length; i++) { if (nums[i] > 0 ) { return i + 1 ; } } return nums.length + 1 ; }
【数组】,【分治】、【快速选择】、【排序】、【堆】
给定整数数组 nums 和整数 k,请返回数组中第 **k** 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
提示:
1 <= k <= nums.length <= 105
-104 <= nums[i] <= 104
示例:
1 2 3 4 5 输入: [3,2,1,5,6,4], k = 2 输出: 5 输入: [3,2,3,1,2,4,5,5,6], k = 4 输出: 4
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { int quickselect (int [] nums, int l, int r, int k) { if (l == r) { return nums[k]; } int x = nums[l], i = l - 1 , j = r + 1 ; while (i < j) { do { i++; } while (nums[i] < x); do { j--; } while (nums[j] > x); if (i < j) { int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp; } } if (k <= j) { return quickselect(nums, l, j, k); } return quickselect(nums, j + 1 , r, k); } public int findKthLargest (int [] _nums, int k) { int n = _nums.length; return quickselect(_nums, 0 , n - 1 , n - k); } }
矩阵 【数组】,【哈希表】,【矩阵】
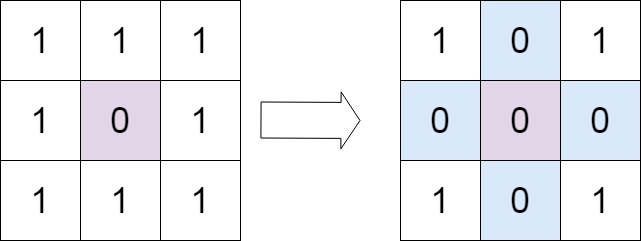
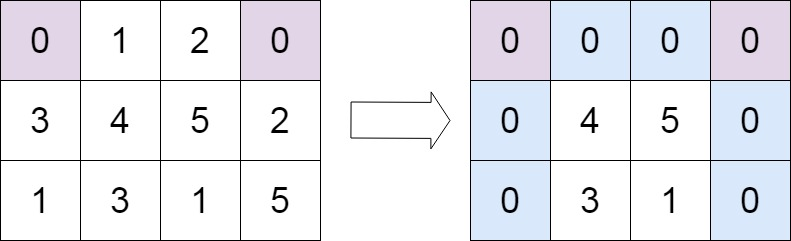
给定一个 *m* x *n* 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地
进阶:
一个直观的解决方案是使用 O(*mn*) 的额外空间,但这并不是一个好的解决方案。
一个简单的改进方案是使用 O(*m* + *n*) 的额外空间,但这仍然不是最好的解决方案。
你能想出一个仅使用常量空间的解决方案吗?
提示:
m == matrix.length
n == matrix[0].length
1 <= m, n <= 200
231 <= matrix[i][j] <= 231 - 1
示例:
1 2 输入:matrix = [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]
1 2 输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]] 输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public void setZeroes (int [][] matrix) { boolean isFirstRowZero = false ; boolean isFirstColZero = false ; for (int i = 0 ; i < matrix.length; i++) { if (matrix[i][0 ] == 0 ) { isFirstColZero = true ; break ; } } for (int j = 0 ; j < matrix[0 ].length; j++) { if (matrix[0 ][j] == 0 ) { isFirstRowZero = true ; break ; } } for (int i = 1 ; i < matrix.length; i++) { for (int j = 1 ; j < matrix[i].length; j++) { if (matrix[i][j] == 0 ) { matrix[i][0 ] = 0 ; matrix[0 ][j] = 0 ; } } } for (int i = 1 ; i < matrix.length; i++) { if (matrix[i][0 ] == 0 ) { Arrays.fill(matrix[i], 0 ); } } for (int j = 1 ; j < matrix[0 ].length; j++) { if (matrix[0 ][j] == 0 ) { for (int i = 0 ; i < matrix.length; i++) { matrix[i][j] = 0 ; } } } if (isFirstRowZero) { Arrays.fill(matrix[0 ], 0 ); } if (isFirstColZero) { for (int i = 0 ; i < matrix.length; i++) { matrix[i][0 ] = 0 ; } } }
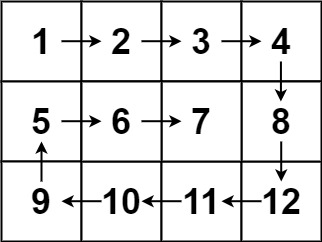
【数组】,【矩阵】,【模拟】
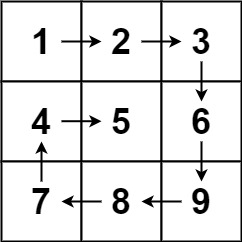
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 10
100 <= matrix[i][j] <= 100
示例:
1 2 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]
1 2 输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] 输出:[1,2,3,4,8,12,11,10,9,5,6,7]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public List<Integer> spiralOrder (int [][] matrix) { List<Integer> res = new ArrayList <>(); if (matrix == null || matrix.length == 0 || matrix[0 ].length == 0 ) { return res; } int rows = matrix.length; int cols = matrix[0 ].length; int top = 0 , bottom = rows - 1 , left = 0 , right = cols - 1 ; while (top <= bottom && left <= right) { for (int i = left; i <= right; i++) { res.add(matrix[top][i]); } top++; for (int i = top; i <= bottom; i++) { res.add(matrix[i][right]); } right--; if (top <= bottom) { for (int i = right; i >= left; i--) { res.add(matrix[bottom][i]); } bottom--; } if (left <= right) { for (int i = bottom; i >= top; i--) { res.add(matrix[i][left]); } left++; } } return res; }
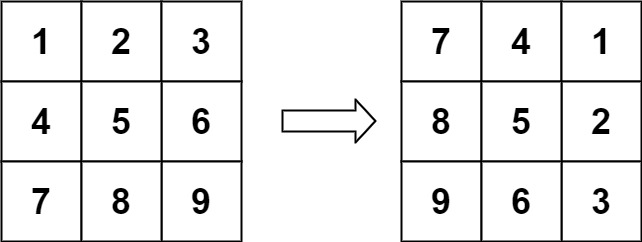
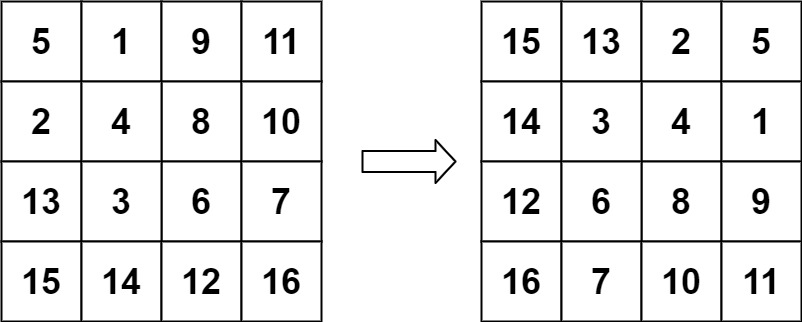
【数组】,【数学】,【矩阵】
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 请不要 使用另一个矩阵来旋转图像。
提示:
n == matrix.length == matrix[i].length
1 <= n <= 20
1000 <= matrix[i][j] <= 1000
示例:
1 2 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[[7,4,1],[8,5,2],[9,6,3]]
1 2 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]] 输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public void rotate (int [][] matrix) { int n = matrix.length; for (int i = 0 ; i < n / 2 ; i++) { for (int j = 0 ; j < (n + 1 ) / 2 ; j++) { int tmp = matrix[i][j]; matrix[i][j] = matrix[n - 1 - j][i]; matrix[n - 1 - j][i] = matrix[n - 1 - i][n - 1 - j]; matrix[n - 1 - i][n - 1 - j] = matrix[j][n - 1 - i]; matrix[j][n - 1 - i] = tmp; } } }
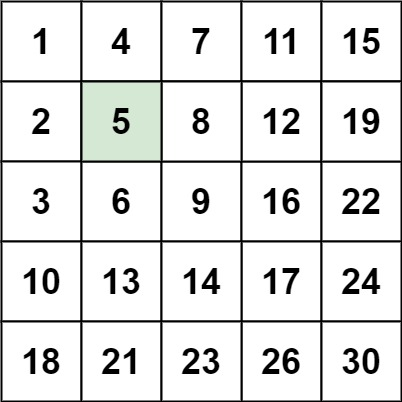
【数组】、【二分查找】、【分治】、【矩阵】
编写一个高效的算法来搜索 *m* x *n* 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
提示:
m == matrix.length
n == matrix[i].length
1 <= n, m <= 300
109 <= matrix[i][j] <= 109
每行的所有元素从左到右升序排列
每列的所有元素从上到下升序排列
109 <= target <= 109
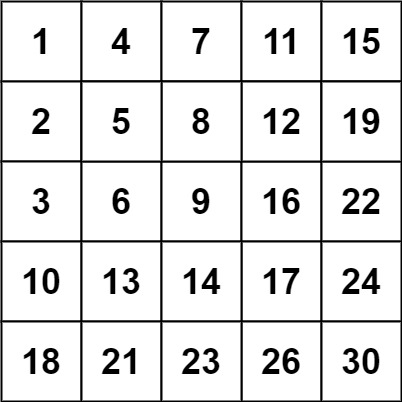
示例:
1 2 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5 输出:true
1 2 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20 输出:false
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 public boolean searchMatrix (int [][] matrix, int target) { int top = 0 , bottom = matrix.length - 1 ; while (top <= bottom) { int left = 0 , right = matrix[0 ].length - 1 ; while (left <= right && matrix[top][right] >= target) { int mid = (left + right) / 2 ; if (matrix[top][mid] == target) { return true ; } else if (matrix[top][mid] > target) { right = mid - 1 ; } else { left = mid + 1 ; } } top++; if (matrix[bottom][0 ] > target) { bottom--; } } return false ; } public boolean searchMatrix (int [][] matrix, int target) { int left = 0 , bottom = matrix.length - 1 ; while (left <= matrix[0 ].length - 1 && bottom >= 0 ) { if (matrix[bottom][left] == target) { return true ; } if (matrix[bottom][left] > target) { bottom--; } else { left++; } } return false ; }
链表 【】,【】
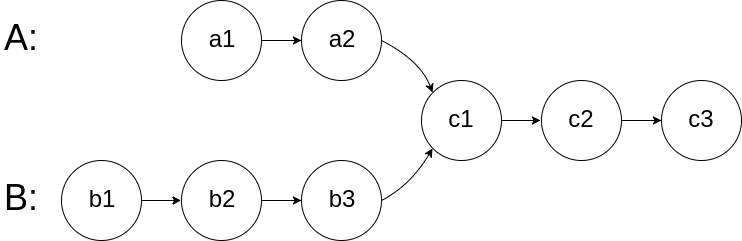
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交**:**
题目数据 保证 整个链式结构中不存在环。
注意 ,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0listA - 第一个链表listB - 第二个链表skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
**进阶:**你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
示例:
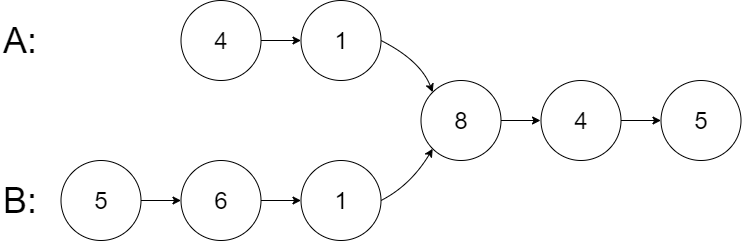
1 2 3 4 5 6 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3 输出:Intersected at '8' 解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。 在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。 — 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
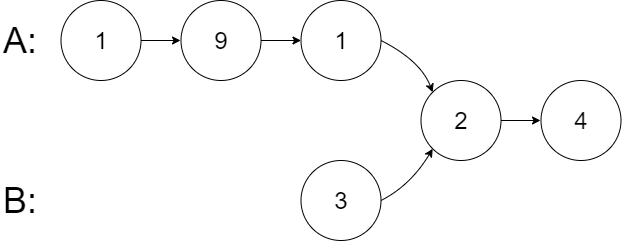
1 2 3 4 5 输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 输出:Intersected at '2' 解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。 在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
1 2 3 4 5 输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2 输出:No intersection 解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。 由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。 这两个链表不相交,因此返回 null 。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 public ListNode getIntersectionNode (ListNode headA, ListNode headB) { if (headA == null || headB == null ) { return null ; } ListNode a = headA, b = headB; while (a != null || b != null ) { if (a == b) { return a; } a = a == null ? headB : a.next; b = b == null ? headA : b.next; } return null ; } public ListNode getIntersectionNode (ListNode headA, ListNode headB) { ListNode aList = headA; ListNode bList = headB; while (aList != null && bList != null ) { aList = aList.next; bList = bList.next; } while (aList != null ) { headA = headA.next; aList = aList.next; } while (bList != null ) { headB = headB.next; bList = bList.next; } while (headA != headB) { headA = headA.next; headB = headB.next; } return headA; }
【递归】、【链表】
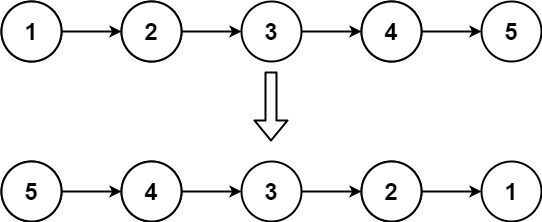
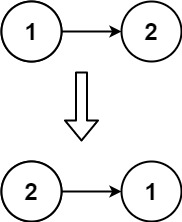
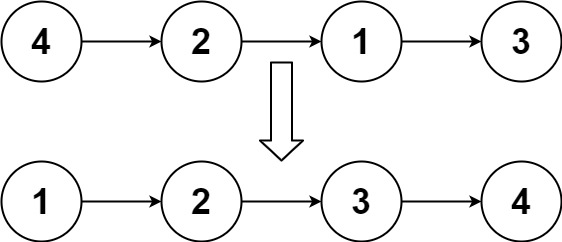
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
**进阶:**链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
提示:
链表中节点的数目范围是 [0, 5000]
5000 <= Node.val <= 5000
示例:
1 2 输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]
1 2 输入:head = [1,2] 输出:[2,1]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public ListNode reverseList (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode pre = new ListNode (head.val); while (head.next != null ) { ListNode current = new ListNode (head.next.val); head = head.next; current.next = pre; pre = current; } return pre; }
【栈】、【递归】、【链表】、【双指针】
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
提示:
链表中节点数目在范围[1, 105] 内
0 <= Node.val <= 9
示例:
1 2 输入:head = [1,2,2,1] 输出:true
1 2 输入:head = [1,2] 输出:false
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public ListNode reverseList (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode cur = head; ListNode pre = null ; while (cur != null ) { ListNode next = cur.next; cur.next = pre; pre = cur; cur = next; } return pre; } public boolean isPalindrome (ListNode head) { if (head == null || head.next == null ) { return true ; } ListNode fast = head; ListNode slow = head; while (fast.next != null && fast.next.next != null ) { fast = fast.next.next; slow = slow.next; } ListNode listNode = reverseList(slow.next); while (listNode != null ) { if (listNode.val != head.val) { return false ; } listNode = listNode.next; head = head.next; } return true ; }
【递归】、【链表】、【数学】
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表
提示:
每个链表中的节点数在范围 [1, 100] 内
0 <= Node.val <= 9
题目数据保证列表表示的数字不含前导零
示例:
1 2 3 输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807
1 2 输入:l1 = [0], l2 = [0] 输出:[0]
1 2 输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9] 输出:[8,9,9,9,0,0,0,1]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public ListNode addTwoNumbers (ListNode l1, ListNode l2) { ListNode dummyHead = new ListNode (); ListNode current = dummyHead; int carry = 0 ; while (l1 != null || l2 != null || carry != 0 ) { int sum = carry; if (l1 != null ) { sum += l1.val; l1 = l1.next; } if (l2 != null ) { sum += l2.val; l2 = l2.next; } carry = sum / 10 ; current.next = new ListNode (sum % 10 ); current = current.next; } return dummyHead.next; }
【哈希表】、【链表】、【双指针】
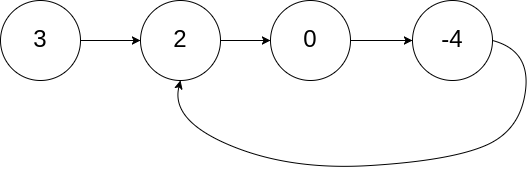
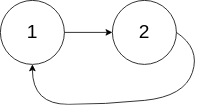
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
**进阶:**你能用 O(1)(即,常量)内存解决此问题吗?
提示:
链表中节点的数目范围是 [0, 104]
105 <= Node.val <= 105
pos 为 1 或者链表中的一个 有效索引 。
示例:
1 2 3 输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
1 2 3 输入:head = [1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。
1 2 3 输入:head = [1], pos = -1 输出:false 解释:链表中没有环。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public boolean hasCycle (ListNode head) { if (head == null || head.next == null ) { return false ; } ListNode fast = head.next; ListNode slow = head; while (fast != slow) { if (fast == null || fast.next == null ) { return false ; } fast = fast.next.next; slow = slow.next; } return true ; }
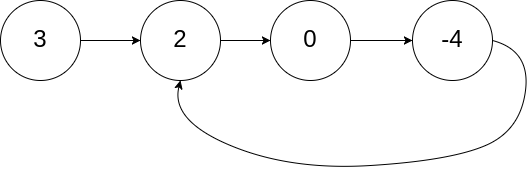
【哈希表】、【链表】、【双指针】
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始 )。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递 ,仅仅是为了标识链表的实际情况。
不允许修改 链表。
**进阶:**你是否可以使用 O(1) 空间解决此题?
提示:
链表中节点的数目范围在范围 [0, 104] 内
105 <= Node.val <= 105
pos 的值为 1 或者链表中的一个有效索引
示例:
1 2 3 输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
1 2 3 输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
1 2 3 输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public ListNode detectCycle (ListNode head) { if (head == null || head.next == null ) { return null ; } ListNode fast = head; ListNode slow = head; while (fast != null && fast.next != null && slow.next != null ) { fast = fast.next.next; slow = slow.next; if (fast == slow) { ListNode pre = head; while (pre != slow) { pre = pre.next; slow = slow.next; } return pre; } } return null ; }
【递归】、【链表】
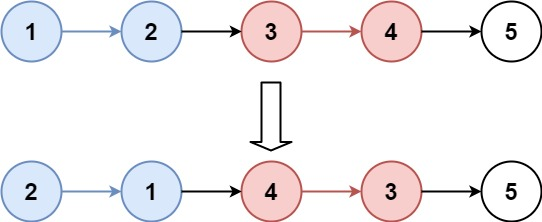
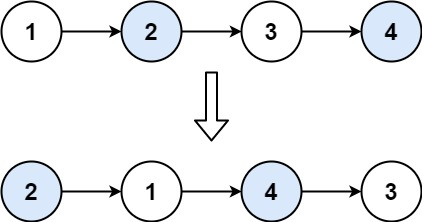
给你链表的头节点 head ,每 k **个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k **的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
**进阶:**你可以设计一个只用 O(1) 额外内存空间的算法解决此问题吗?
提示:
链表中的节点数目为 n
1 <= k <= n <= 5000
0 <= Node.val <= 1000
示例:
1 2 输入:head = [1,2,3,4,5], k = 2 输出:[2,1,4,3,5]
1 2 输入:head = [1,2,3,4,5], k = 3 输出:[3,2,1,4,5]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public ListNode reverseKGroup (ListNode head, int k) { if (head == null || k <= 1 ) { return head; } ListNode dummy = new ListNode (0 ); dummy.next = head; ListNode prevGroupEnd = dummy; while (true ) { ListNode kthNode = getKthNode(prevGroupEnd, k); if (kthNode == null ) { break ; } ListNode nextGroupStart = kthNode.next; ListNode[] reversedGroup = reverseList(prevGroupEnd.next, k); prevGroupEnd.next = reversedGroup[0 ]; prevGroupEnd = reversedGroup[1 ]; prevGroupEnd.next = nextGroupStart; } return dummy.next; } private ListNode getKthNode (ListNode start, int k) { while (start != null && --k >= 0 ) { start = start.next; } return start; } private ListNode[] reverseList(ListNode head, int k) { ListNode prev = null ; ListNode cur = head; ListNode next = null ; for (int i = 0 ; i < k; i++) { next = cur.next; cur.next = prev; prev = cur; cur = next; } return new ListNode [] {prev, head}; }
【链表】、【双指针】
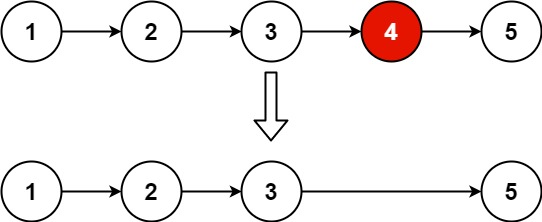
给你一个链表,删除链表的倒数第 n **个结点,并且返回链表的头结点。
**进阶:**你能尝试使用一趟扫描实现吗?
提示:
链表中结点的数目为 sz
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz
示例:
1 2 输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
1 2 输入:head = [1], n = 1 输出:[]
1 2 输入:head = [1,2], n = 1 输出:[1]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public ListNode removeNthFromEnd (ListNode head, int n) { ListNode dummy = new ListNode (0 , head); int length = getLength(head); ListNode cur = dummy; for (int i = 1 ; i < length - n + 1 ; ++i) { cur = cur.next; } cur.next = cur.next.next; ListNode ans = dummy.next; return ans; } public int getLength (ListNode head) { int length = 0 ; while (head != null ) { ++length; head = head.next; } return length; }
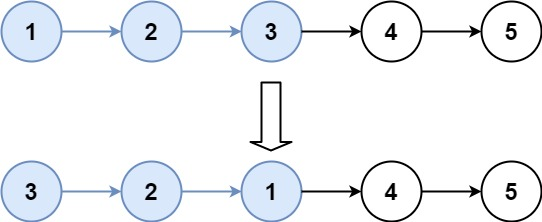
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
提示:
链表中节点的数目在范围 [0, 100] 内
0 <= Node.val <= 100
示例:
1 2 输入:head = [1,2,3,4] 输出:[2,1,4,3]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public ListNode swapPairs (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode dumpNode1 = new ListNode (0 , head); ListNode dumpNode = dumpNode1; while (dumpNode.next != null && dumpNode.next.next != null ) { ListNode temp2 = dumpNode.next.next; ListNode temp1 = dumpNode.next; dumpNode.next = temp2; temp1.next = temp2.next; temp2.next = temp1; dumpNode = temp1; } return dumpNode1.next; }
【链表】、【分治】、【堆】、【归并排序】
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
提示:
k == lists.length
0 <= k <= 10^4
0 <= lists[i].length <= 500
10^4 <= lists[i][j] <= 10^4
lists[i] 按 升序 排列
lists[i].length 的总和不超过 10^4
示例:
1 2 3 4 5 6 7 8 9 10 输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public ListNode mergeKLists (ListNode[] lists) { if (lists == null || lists.length == 0 ) { return null ; } return mergeKListsHelper(lists, 0 , lists.length - 1 ); } private ListNode mergeKListsHelper (ListNode[] lists, int start, int end) { if (start == end) { return lists[start]; } if (start > end) { return null ; } int mid = start + (end - start) / 2 ; ListNode left = mergeKListsHelper(lists, start, mid); ListNode right = mergeKListsHelper(lists, mid + 1 , end); return mergeTwoLists(left, right); } private ListNode mergeTwoLists (ListNode l1, ListNode l2) { ListNode dummy = new ListNode (0 ); ListNode current = dummy; while (l1 != null && l2 != null ) { if (l1.val < l2.val) { current.next = l1; l1 = l1.next; } else { current.next = l2; l2 = l2.next; } current = current.next; } if (l1 != null ) { current.next = l1; } else { current.next = l2; } return dummy.next; }
【链表】、【归并排序】
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
提示:
两个链表的节点数目范围是 [0, 50]
100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
示例:
1 2 输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public ListNode mergeTwoLists (ListNode l1, ListNode l2) { if (l1 == null ) { return l2; } else if (l2 == null ) { return l1; } else if (l1.val < l2.val) { l1.next = mergeTwoLists(l1.next, l2); return l1; } else { l2.next = mergeTwoLists(l1, l2.next); return l2; } } }
【哈希表】、【链表】
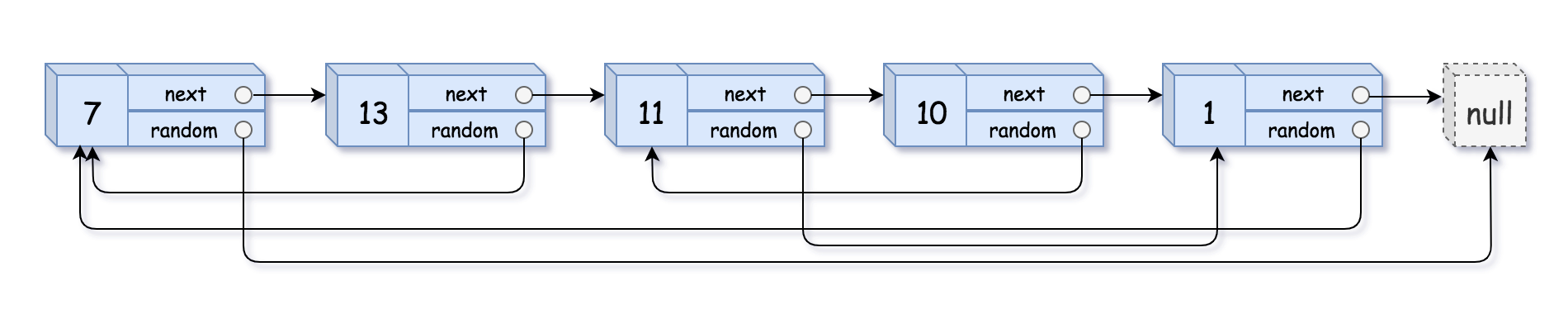
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
提示:
0 <= n <= 1000
104 <= Node.val <= 104
Node.random 为 null 或指向链表中的节点。
示例:
1 2 输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
1 2 输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
1 2 输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public Node copyRandomList (Node head) { if (head == null ) { return null ; } Node current = head; while (current != null ) { Node newNode = new Node (current.val); newNode.next = current.next; current.next = newNode; current = newNode.next; } current = head; while (current != null ) { if (current.random != null ) { current.next.random = current.random.next; } current = current.next.next; } current = head; Node newHead = head.next; Node newCurrent = newHead; while (newCurrent.next != null ) { current.next = current.next.next; newCurrent.next = newCurrent.next.next; current = current.next; newCurrent = newCurrent.next; } current.next = null ; return newHead; }
【链表】、【双指针】、【分治】、【排序】、【归并排序】
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
**进阶:**你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
提示:
链表中节点的数目在范围 [0, 5 * 104] 内
105 <= Node.val <= 105
示例:
1 2 输入:head = [4,2,1,3] 输出:[1,2,3,4]
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public ListNode sortList (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode mid = findMiddle(head); ListNode rightHead = mid.next; mid.next = null ; ListNode left = sortList(head); ListNode right = sortList(rightHead); return merge(left, right); } private ListNode findMiddle (ListNode head) { ListNode slow = head, fast = head; while (fast != null && fast.next != null ) { fast = fast.next.next; if (fast == null || fast.next == null ) { break ; } slow = slow.next; } return slow; } private ListNode merge (ListNode l1, ListNode l2) { ListNode dummy = new ListNode (0 ); ListNode cur = dummy; while (l1 != null && l2 != null ) { if (l1.val < l2.val) { cur.next = l1; l1 = l1.next; } else { cur.next = l2; l2 = l2.next; } cur = cur.next; } cur.next = l1 != null ? l1 : l2; return dummy.next; }
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 1 。void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 put
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 输入 ["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"] [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]] 输出 [null, null, null, 1, null, -1, null, -1, 3, 4] 解释 LRUCache lRUCache = new LRUCache(2); lRUCache.put(1, 1); // 缓存是 {1=1} lRUCache.put(2, 2); // 缓存是 {1=1, 2=2} lRUCache.get(1); // 返回 1 lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3} lRUCache.get(2); // 返回 -1 (未找到) lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3} lRUCache.get(1); // 返回 -1 (未找到) lRUCache.get(3); // 返回 3 lRUCache.get(4); // 返回 4
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 public class LRUCache { class DLinkedNode { int key; int value; DLinkedNode prev; DLinkedNode next; public DLinkedNode () {} public DLinkedNode (int _key, int _value) {key = _key; value = _value;} } private Map<Integer, DLinkedNode> cache = new HashMap <Integer, DLinkedNode>(); private int size; private int capacity; private DLinkedNode head, tail; public LRUCache (int capacity) { this .size = 0 ; this .capacity = capacity; head = new DLinkedNode (); tail = new DLinkedNode (); head.next = tail; tail.prev = head; } public int get (int key) { DLinkedNode node = cache.get(key); if (node == null ) { return -1 ; } moveToHead(node); return node.value; } public void put (int key, int value) { DLinkedNode node = cache.get(key); if (node == null ) { DLinkedNode newNode = new DLinkedNode (key, value); cache.put(key, newNode); addToHead(newNode); ++size; if (size > capacity) { DLinkedNode tail = removeTail(); cache.remove(tail.key); --size; } } else { node.value = value; moveToHead(node); } } private void addToHead (DLinkedNode node) { node.prev = head; node.next = head.next; head.next.prev = node; head.next = node; } private void removeNode (DLinkedNode node) { node.prev.next = node.next; node.next.prev = node.prev; } private void moveToHead (DLinkedNode node) { removeNode(node); addToHead(node); } private DLinkedNode removeTail () { DLinkedNode res = tail.prev; removeNode(res); return res; } }