Nacos基本原理(一)
重点关注naming/config模块、基于plugin模块开发自定义插件(如数据源适配)、扩展core模块的通信框架(gRPC/HTTP)
| 版本 | 默认协议 | 特点 | 配置方式 |
|---|---|---|---|
| 1.x | HTTP | 短连接,性能低 | 无需额外配置 |
| 2.x | gRPC | 长连接,性能提升 10 倍 | 临时实例自动启用(ephemeral=true) |
| 3.x | gRPC + QUIC | 支持 AI Agent 场景,强化安全隔离 | 默认启用,可通过插件扩展协议 |
关键版本升级点:
2.0
- gRPC 替代 HTTP 提升吞吐量。
- 插件化架构(如自定义鉴权模块)
3.0
- 安全增强:分离控制台 API 与服务 API 端口,支持命名空间统一管理
- AI 支持:优化轻量化 Agent 的注册发现机制(如 Serverless 场景)
服务注册和发现(健康检查)
服务注册机制
- 客户端自动注册触发机制
- 入口:Spring Boot 项目引入
spring-cloud-starter-alibaba-nacos-discovery后,通过spring.factories加载自动配置类NacosServiceRegistryAutoConfiguration。 - 关键 Bean:
NacosServiceRegistry:实现ServiceRegistry接口,负责注册逻辑。NacosRegistration:封装实例信息(IP、端口、服务名)。NacosAutoServiceRegistration:继承AbstractAutoServiceRegistration,监听WebServerInitializedEvent事件(Web 服务启动完成后触发注册)
- 事件触发源码:
1 |
|
- 注册请求发起关键源码
- 组装实例信息
NacosServiceRegistry#register() 将 Spring 的 Registration 对象转为 Nacos 的 Instance 对象:
1 | java |
- 协议选择与请求发送(版本差异重点)
NamingService#registerInstance() 的实现类 NacosNamingService 根据实例类型选择协议:
1 | public void registerInstance(String serviceName, String groupName, Instance instance) { |
- 协议选择逻辑:
1 | private NamingClientProxy getExecuteClientProxy(Instance instance) { |
协议主动切换
客户端配置:Nacos客户端通过配置参数明确指定协议类型,优先级高于默认行为:
1
2
3
4
5
6# HTTP协议配置 Spring Cloud Alibaba项目
spring.cloud.nacos.discovery.protocol=http # 服务发现协议
spring.cloud.nacos.config.protocol=http # 配置管理协议
gRPC协议配置(2.x默认)
spring.cloud.nacos.discovery.protocol=grpc协议底层实现逻辑
Nacos客户端封装了协议适配层,通过工厂模式动态创建协议处理器:
- 客户端初始化流程:
- 解析配置参数(如
protocol=http)。 - 通过
ProtocolManager工厂创建NamingClientProxy实例(HttpClientProxy或GrpcClientProxy)。 - 所有请求(注册、心跳、查询)交由协议代理类处理。
- 解析配置参数(如
3. 服务端兼容性
- HTTP/gRPC双端口监听:
- HTTP:默认端口
8848,兼容1.x客户端。网络策略禁止长连接(如某些安全组规则),兼容旧基础设施(如HTTP代理) - gRPC:默认端口
9848(8848+1000),供2.x客户端使用。gRPC优势:长连接、多路复用,吞吐量提升50%+,适合高并发场景5
- HTTP:默认端口
- 服务端协议识别:根据请求端口和协议头自动路由到对应处理模块,无需额外配置
- 客户端初始化流程:
服务端兼容性
- 服务端处理流程
- 请求入口
服务注册请求由 InstanceController 处理:
1 | java |
- 注册表存储结构
服务端使用双层ConcurrentHashMap存储注册信息:
1 |
|
- Service 对象:包含集群列表(
Cluster),每个集群维护实例列表(Instance)
配置说明:
临时实例:将Instance加入内存注册表 (ConcurrentHashMap<String, Service>结构)。实例启动后台心跳检查线程池。Server 不会主动持久化到数据库
- Client 端定期(默认5秒)向 Server 发送HTTP PUT
/nacos/v1/ns/instance/beat心跳包,包含自身InstanceID - Server 端 (
DistroConsistencyServiceImpl) 收到心跳,更新内存注册表中对应Instance的lastBeat(最后心跳时间戳)
1 | spring: |
持久实例:将 Instance 信息同步写入数据库(MySQL等)。Server 依赖客户端显式调用注销接口 (Deregister) 或配置的主动健康检查机制(如TCP/HTTP/Mysql探活)来移除
1 | spring: |
服务发现流程
核心的naming模块
- 消费者
NacosNamingService通过getInstances(serviceName)获取服务实例列表。首次调用会同步拉取全量ServiceInfo触发订阅 - 订阅触发: Client 发起 HTTP POST
/nacos/v1/ns/instance/list请求订阅指定服务(serviceName); - Server 端推送机制:
- UDP 优先 (默认): Server 监听到注册表变更(新注册、心跳超时、注销)时,会立即生成一个携带变更 Service 名称的任务,放入异步队列。处理线程向所有订阅了该 Service 的 Client 目标 UDP 端口 (默认:端口偏移量1000) 发送变更通知 (
ServiceInfo摘要信息)。 - HTTP 兜底 (Pull): Client 端后台维护一个定时任务(默认每10秒执行一次 -
pushReceiverTask),主动发起HTTP GET/nacos/v1/ns/instance/list拉取最新ServiceInfo。 - 混合模式: UDP通知极速触发拉取(Client收到UDP通知后立即发起一次HTTP拉取),HTTP长轮询兜底保证可靠性。
pushEmptyProtection(默认true) 是一个关键容错参数:当Service下所有实例因故被移除(非正常下线),Server会返回包含"instances": []的空列表给Client,防止Client因接收不到UDP通知而误判无可用实例(旧缓存数据),触发Client本地缓存清理。示例:一个Service因网络分区所有实例被Server误剔,若无此参数,Consumer仍持有旧缓存可能调用失败;设置后,Consumer会收到空列表,清缓存,避免调用无效节点。
- UDP 优先 (默认): Server 监听到注册表变更(新注册、心跳超时、注销)时,会立即生成一个携带变更 Service 名称的任务,放入异步队列。处理线程向所有订阅了该 Service 的 Client 目标 UDP 端口 (默认:端口偏移量1000) 发送变更通知 (
- 动态感知实例下线 (Consumer)
- 心跳超时移除: Server端的心跳检查任务 (
ClientBeatCheckTask) 定期(默认15秒扫描间隔,阈值20秒超时) 检查内存注册表中所有临时实例的lastBeat。若当前时间 -lastBeat > 心跳超时时间(默认15s),则将其健康状态标记为false,并在后续一次扫描(默认15s后) 如果仍未收到心跳,则将其从注册表中移除。移除动作立即触发变更通知(UDP)。 - 主动注销 (Provider): Provider 关闭前主动调用
deregisterInstance(),发送 HTTP DELETE/nacos/v1/ns/instance。Server 移除实例,立即触发变更通知(UDP)。 - Consumer:
- 收到 UDP 变更通知,立即发起一次 HTTP 请求 拉取最新
ServiceInfo,更新本地缓存和负载均衡器。 - HTTP 兜底轮询(默认10秒) 也会拉取最新信息更新缓存。
- 结合
ServiceInfo中的hosts列表(当前健康实例) 和本地监听器回调(EventNotifier),Ribbon等负载均衡组件能快速切换可用实例。典型场景:某个Provider实例所在机器宕机导致心跳停止,约20+15=35秒(理论最坏情况,实践中UDP通知能大幅缩短)内,Consumer将感知到该实例不可用并从负载均衡器中摘除
- 收到 UDP 变更通知,立即发起一次 HTTP 请求 拉取最新
- 心跳超时移除: Server端的心跳检查任务 (
健康检查
- 临时实例(Ephemeral):客户端每 5 秒发送心跳,服务端若 15 秒未收到心跳标记为不健康,30 秒未收到则剔除。(动态扩缩容场景(如秒杀活动),默认通过客户端心跳上报)
- 持久实例(Persistent):服务端主动发起 HTTP 健康检查。(常备服务(如数据库主节点),通过服务端主动探测)
- 临时实例先注册后启动心跳,避免服务端未收到心跳误剔除
健康检查线程调度池
临时实例的健康检查(客户端心跳上报)
- 流程原理
- 注册与心跳启动:服务启动时向Nacos注册,成功后启动后台线程(
BeatReactor)定期发送心跳包。心跳周期:默认5秒(可通过spring.cloud.nacos.discovery.heart-beat-interval调整)。 - 服务端状态判断:15秒未收到心跳(如连续3次丢失):标记实例为不健康(
healthy=false)。30秒未收到心跳:从注册表移除实例。 - 心跳包内容:HTTP请求:
PUT /nacos/v1/ns/instance/beat?serviceName=xxx&ip=xxx&port=xxx - 特点:
- 优点:轻量级(客户端主动上报,服务端压力小)、响应快(秒级感知故障);
- 缺点:若客户端进程假死(仍能发送心跳),服务端无法感知真实状态;
- 注册与心跳启动:服务启动时向Nacos注册,成功后启动后台线程(
- 流程原理
持久实例的健康检查(服务端主动探测)
流程原理
探测触发:Nacos服务端启动定时任务,按配置协议主动探测实例。
探测周期:2000毫秒 + 随机延迟(<5000毫秒)。
探测协议与逻辑:TCP探测:尝试与实例的IP:端口建立TCP连接,成功即视为健康。HTTP探测:发送GET/POST请求,检查返回状态码是否为2xx(如200)。MySQL探测:执行简单SQL(如
SELECT 1),验证数据库可访问性。状态更新:探测失败时标记实例为不健康,但不会立即删除(需手动剔除)
配置方式: 支持元数据(metadata)指定探测参数
1
2
3
4
5metadata:
checkType: "HTTP" # 协议类型(HTTP/TCP/MySQL)
checkPort: "8080" # 探测端口(默认实例端口)
checkPath: "/health" # HTTP探测路径
expectedResponseCode: "200" # 期望HTTP状态码
集群模式下的健康检查同步
主节点负责制:每个服务由集群中一个主节点(Leader)负责健康检查;临时实例:主节点接受心跳后,同步状态给其他节点;持久实例:主节点探测后同步结果,数据一致性,Raft协议等等
自我保护机制:设置保护阈值(0 ~ 1,默认0.8): 当健康实例占比低于阈值时,继续向不健康实例路由流量,避免剩余实例被压垮(牺牲部分请求保整体可用);
参数调优建议:缩短心跳间隔(如
heart-beat-interval=1s)以加速故障感知,减少探测频率(如interval-ms=10000)以降低服务端压力。协议选择场景:需验证业务接口可用性(如Spring Boot Actuator的
/actuator/health),仅验证网络连通性,开销最小
动态配置管理
核心机制:监听与长轮询改进
核心机制:监听与长轮询改进
ConfigService.addListener(dataId, group, Listener): Client添加对某个配置(dataId+group)的监听器。ClientWorker与LongPollingRunnable: Client端核心组件,管理监听器和长轮询任务。- 核心流程 - “长轮询改进” (Server-Center模块):
- 发起长轮询 (Client): 监听线程(
LongPollingRunnable) 发起 HTTP POST/nacos/v1/cs/configs/listener。请求体包含它关心的所有dataId+group及其contentMd5(当前客户端本地配置内容的MD5值,用于标识版本)。关键参数:Listening-Configs(加密的监听配置列表),timeout(长轮询超时时间, 默认30s -configLongPollTimeout)。 - Server端处理:
- 检查传入
dataId+group是否被修改过(比对Server端存储的最新contentMd5)。若任一配置有变更,立即返回该变化的dataId+group给Client。 - 若无变更,Server端将此连接挂起(使用
Servlet 3.0 AsyncContext异步支持),放入一个Map<String, List<ClientLongPolling>>结构(Key: GroupKey=dataId+group) 等待队列。
- 检查传入
- 触发变更推送 (Server): 当有配置更新时,发布事件的线程 (
ConfigDataChangeEvent):- 计算新配置的
contentMd5。 - 查找对应
GroupKey的所有挂起连接 (List<ClientLongPolling>)。 - 批量响应 (Batch Push): 立即向所有挂起的连接响应,携带变更的
GroupKey。这不是点对点UDP,而是对等待该GroupKey变更的所有客户端的长连接进行批量响应。
- 计算新配置的
- Client处理响应:
- 如果在
timeout(30s) 内收到了Server的响应(无论返回变更还是超时返回304),则:- 若返回304(
no change),等待下一次长轮询。 - 若返回了变化的
dataId+group,立即发起一次HTTP GET/v1/cs/configs拉取该配置项的最新内容(含所有内容)。
- 若返回304(
- 如果30秒内Server端无任何配置变更,则Server会返回 HTTP 304 Not Modified。Client收到后,稍作延迟(随机),立即发起下一次长轮询请求
- 如果在
- 发起长轮询 (Client): 监听线程(
- 核心优势 (vs 短轮询):
- 大幅度减少无效请求: 短轮询需要客户端频繁(如每秒)查询,无论有无变更。长轮询在无变更时最大30s才有一个请求(短轮询30个)。大大节省Server资源。
- 准实时: 变更发生后,通过挂起连接批量响应,能实现秒级(甚至毫秒级) 的变更通知,接近实时推送。拉取配置内容(HTTP GET)是紧随通知后的动作。
- 兜底机制: 长轮询超时确保了连接不会永久挂起,提供了可靠性。
configLongPollTimeout是关键调优参数:设置过大,单连接占用资源久;设置过小,可能导致轮询过于频繁。默认30s是平衡点。 - 典型场景:微服务中动态日志级别调整。在Nacos控制台修改
application.yml中logging.level.com.example的配置,ConfigService监听到变更,应用无需重启就能即时调整日志输出级别
集群与一致性协议
多模式一致性协议
对比Eureka、Consul等竞品的差异、脑裂问题的处理
AP模式:(Distro协议):临时实例采用自研Distro协议(异步复制),保证高可用
- 核心机制 (最终一致性):
- 注册中心场景专用(临时实例)/配置中心默认。 Distro 是 Nacos 自研的最终一致性协议。
- 节点对等 & 分片责任: 集群内所有节点地位平等。每个节点负责集群中一部分数据分片 (基于
Service Name或DataID的哈希分片)。每个节点负责自己分片数据的主写和主读(对于其负责分片的写请求,该节点是事实上的“Leader”)。 - 写流程:
- Client 可以写任意节点(Server A)。
- Server A 判断该数据
Key(如Service Name)是否属于自己的责任分片:- 是: 写入本地内存并立即响应Client成功。然后将写操作异步复制 (
DistroProtocol) 给其他所有节点。复制成功与否不阻塞Client响应。 - 否: Server A 将请求 重定向 (
redirect()) 到计算出的该Key的责任节点(Server B)。由Server B负责其分片数据的处理和复制。DistroConsistencyServiceImpl处理此逻辑。
- 是: 写入本地内存并立即响应Client成功。然后将写操作异步复制 (
- 读流程: Client可以读任意节点。节点返回自己当前内存中的最新数据(最终一致性,可能不是全局绝对最新)。
- 数据同步 (
DistroTask): 节点间定期(秒级)互相校验全量数据摘要(Digest)或增量数据 (DistroDataProcessor)。通过Gossip协议或直接点对点校验,发现差异后拉取缺失/更新数据。保证最终数据收敛一致。distro.data.sync.retryDelay和distro.data.sync.periodMs控制同步频率。 - 分区容忍: 当发生网络分区时(如两个机房断开):
- 分区内多数派或各分区内部仍能正常读写自己责任分片的数据。
- 但跨分区的责任分片数据不可读写(Client写不属于本分区节点责任分片时会被重定向到另一个分区,因网络不通而失败)。
- 可用性主要体现在分区内部服务注册和发现的连续性,以及配置读取(可能读到旧值)上。典型场景:某应用实例(Provider)在分区A注册成功,分区B的消费者暂时看不到该实例(数据未同步),但分区内消费者和生产者通信正常。分区恢复后数据自动同步。
- 适用场景: 高可用性要求优先,可接受秒级(最终)数据不一致。 例如:微服务注册发现(实例临时上下线)、动态降级限流规则(能感知到即可)、绝大多数业务配置(阈值、开关等)。典型场景:电商大促期间,临时扩容大量服务实例要求快速注册生效,即使有轻微延迟(毫秒到秒)也不影响整体服务调用。
CP模式:(Raft协议):持久实例和配置数据使用Raft协议,保证强一致性
数据写入流程
- 写请求路由:所有写请求(配置发布/服务注册)必须由 Leader 节点处理。若客户端请求发送到 Follower,Follower 会拒绝并返回 Leader 地址(重定向机制)。
- 强一致性保证:
- Leader 将操作封装为 Raft 日志,同步复制到多数节点(N/2+1)。
- 仅当多数节点持久化日志后,Leader 才提交日志并响应客户端成功。
- Leader 选举:Leader 宕机后,集群进入选举状态(通常 3-10 秒),期间所有写请求阻塞,直到新 Leader 产生。
配置更新与拉取
- 配置发布:配置变更通过 Raft 日志同步到多数节点,确保强一致。客户端通过 HTTP 长轮询(默认 30s)感知变更:无变更时请求挂起,变更时立即返回新配置。
- 客户端拉取:客户端首次拉取全量配置并缓存;后续通过监听器(
Listener)和长轮询更新本地缓存。
服务实例更新
- 临时实例注册:需通过 Leader 写入日志并同步多数节点。若 Leader 宕机,注册请求失败(需客户端重试)。
- 健康检查:实例心跳由 Leader 统一处理。若心跳超时(默认 30 秒),Leader 触发日志同步移除实例
对比:
| 特性 | CP模式 (Raft) | AP模式 (Distro) |
|---|---|---|
| 一致性 (C) | 强一致性 (读写线性一致) | 最终一致性 (短暂窗口可能读到旧数据) |
| 可用性 (A) | 选主期间写服务短暂不可用(读可用?) | 读写高可用 (分区内部读写可用) |
| 分区容忍 (P) | 多数派存活可继续服务 | 分区内部能独立提供服务,分区恢复后数据同步 |
| 核心协议 | Raft (Leader选举,日志复制多数派提交) | Distro (分片责任,重定向,异步复制,定期校验) |
| 写扩散 | Leader接收写请求,同步并行复制 | 任意节点接收,责任节点写入并异步复制,批量广播 |
| 读扩散 | 可能Leader读最新(或follower可读已提交?) | 所有节点均可读本地最新(可能滞后) |
| 主节点 | 有明确Leader | 无中心Leader (按分片责任) |
| 适用场景 | 强一致要求高配置、状态锁、基础服务 | 服务注册发现、高可用要求配置、容忍短暂不一致 |
| 配置项 | nacos.core.protocol.raft.data=true |
nacos.core.protocol.raft.data=false (默认) 或 ephemeral=true强制AP |
| 配置更新实时性 | 强一致,变更立即可读 | 最终一致,读可能短暂滞后 |
| 服务注册可用性 | Leader 宕机时注册失败 | 任意节点存活即可注册 |
| 健康检查机制 | Leader 统一管理 | 各节点独立处理 |
集群部署
环境准备
- 节点要求:至少3个节点(奇数个),避免Raft选举脑裂问题。
- 依赖环境:JDK 1.8+(配置
JAVA_HOME,避免使用系统默认JDK)。MySQL 5.7+/8.0(持久化数据,避免使用内嵌Derby)
配置数据库
- 创建数据库
nacos_config,执行conf/nacos-mysql.sql初始化表结构。 - 关键表说明:
config_info:存储配置内容。services/instances:服务注册信息(持久化模式使用)。
- 创建数据库
修改Nacos配置文件
application.properties:注意:MySQL 8需指定时区参数serverTimezone=UTC。1
2
3
4
5
6
7
8properties
复制
# 启用MySQL数据源spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://mysql_ip:3306/nacos_config?charset=utf8&useSSL=false
db.user=root
db.password=your_passwordcluster.conf:复制cluster.conf.example为cluster.conf,添加所有节点IP:确保所有节点配置一致。1
2
3
4
5
6
复制
192.168.1.1:8848
192.168.1.2:8848
192.168.1.3:8848
启动脚本调优
- 修改
bin/startup.sh:- 调整JVM内存参数(如
Xms2g -Xmx2g,避免OOM)。 - 指定端口启动:
./startup.sh -p 8848(避免端口冲突)。
- 调整JVM内存参数(如
- 修改
启动与验证
- 依次启动所有节点:
sh bin/startup.sh。 - 验证集群状态:
- 访问
http://any_node_ip:8848/nacos→ “集群管理”页面,所有节点状态应为UP。 - 检查日志:
logs/start.out无报错,出现Nacos started successfully in cluster mode。
- 访问
- 依次启动所有节点:
接入负载均衡
配置Nginx/SLB,将流量分发到Nacos集群:客户端通过VIP或域名访问(如
nacos.example.com:8848)1
2
3
4
5
6
7
8nginx
复制
upstream nacos_cluster {
server 192.168.1.1:8848;
server 192.168.1.2:8848;
server 192.168.1.3:8848;
}
网络与端口
开放端口:
端口 用途 8848 客户端API及控制台 7848 Raft选举(CP模式) 9848 Distro数据同步(AP模式) 需确保节点间所有端口互通,防火墙放行25。
数据一致性保障
模式选择:
- 服务发现(临时实例)→ AP模式(Distro协议,高可用优先)。
- 配置管理 → CP模式(Raft协议,强一致优先)。
切换命令:
1
2
3
4bash
复制
# 切CP模式
curl -X PUT 'http://nacos-server:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP'常见故障排查:节点无法通信:检查端口占用(
ss -ntlp | grep 7848)及防火墙。数据同步失败:AP模式:查看naming-distro.log,验证Distro同步队列。CP模式:检查naming-raft.log的Leader选举状态。
集群脑裂如何处理?
- Raft协议:通过任期(Term)和多数派投票机制,仅允许多数派分区选举新Leader。
- 预防措施:确保网络分区容忍性(如跨机房专线)、节点时钟同步
对比Eureka的优势?
- 功能:Nacos集成配置管理 + 服务发现,Eureka仅服务发现。
- 一致性:Nacos支持AP/CP切换,Eureka仅AP模式。
- 健康检查:Nacos支持主动探测,Eureka依赖客户端心跳
自我保护和浏览治理
保护阈值
核心原理
- 问题场景:当服务实例大规模故障(如网络抖动或集群雪崩),健康实例占比骤降,剩余健康实例可能因无法承受全部流量而崩溃。
- 保护逻辑:
- 阈值定义:设定一个
0~1的浮点数(如0.5),表示健康实例占比的最小容忍值。 - 触发条件:当健康实例数/总实例数 < 保护阈值时,触发保护机制。
- 行为变化:Nacos 返回全部实例(含不健康实例)给消费者,而非仅健康实例。
- 阈值定义:设定一个
工作流程
- 监控健康状态:Nacos Server 持续检查实例心跳(临时实例)或主动探测(持久实例)。
- 计算健康比例:实时统计健康实例占比。
- 阈值判定:若健康比例低于阈值(如 10 个实例中仅 2 个健康,比例
0.2 < 0.5),则触发保护。 - 返回全量实例:消费者从 Nacos 获取包含不健康实例的列表,负载均衡器可能将部分流量分发到不健康实例(导致部分请求失败,但避免健康实例被压垮)。
作用
- 牺牲部分请求,保全整体:允许部分请求失败(访问不健康实例),但避免健康实例因过载而雪崩。
- 依赖持久化实例:临时实例故障后会被删除,而持久化实例(
ephemeral=false)即使不健康仍保留在列表中,为保护阈值提供“分流底座”
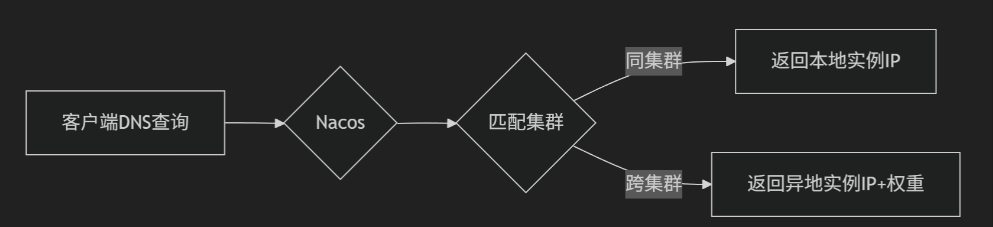
动态DNS与权重路由
流量治理:动态 DNS(Dynamic DNS)
核心原理
- 功能定位:将服务名解析为可动态调整的 IP 列表,支持跨集群路由。
- 工作流程:
- 客户端通过 DNS 协议查询服务名(如
serviceA.default.svc)。 - Nacos 返回该服务健康实例的 IP+Port 列表(自动过滤不健康实例)。
- DNS 响应可附加权重信息,供客户端实现加权轮询。
- 客户端通过 DNS 协议查询服务名(如
高级路由策略
- 基于权重的 DNS 解析:为不同实例 IP 分配不同权重,DNS 响应按权重比例返回 IP,实现客户端侧负载均衡。
- 就近访问(Cluster-Nearby):实例设置
cluster-name(如cluster-shanghai)。消费者优先访问同集群实例,减少跨地域延迟。 - 多级路由策略:
权重作用原理
- 定义:为每个实例分配权重值(默认
1.0,范围0~10000),控制其接收流量的比例。 - 负载均衡逻辑:
- 消费者从 Nacos 获取实例列表及权重。
- 负载均衡器(如 Ribbon、Spring Cloud LoadBalancer)按权重比例分配请求。
- 公式:实例流量占比 = 该实例权重 / 集群总权重。
应用场景
- 性能差异化调度:高性能服务器权重设为
2.0,低性能设为0.5,使高性能机器承担更多流量。 - 灰度发布:新版本实例权重从
0.1逐步提升至1.0,旧版本权重从1.0降至0,实现平滑迁移。 - 故障隔离:疑似故障实例权重设为
0,使其暂时不接收流量,但不注销(便于诊断)
护阈值与流量治理的协同
- 保护阈值触发时:权重路由与动态 DNS 仍生效,但不健康实例也可能被分配流量(权重 > 0 时)。
- 示例:服务设置保护阈值
0.3,实例权重:健康实例1.0,不健康实例0.5。当健康比例<0.3时,不健康实例参与分流(如承担 33% 流量),避免健康实例过载。
参考
- 保护阈值设置:建议
0.3~0.5,过低失去保护意义,过高导致过多失败请求。 - 权重管理:
- 结合监控系统(如 Prometheus)动态调整权重。
- 永久实例权重不低于
0.1,确保保护阈值触发时可参与分流。
- 动态 DNS 适用场景:跨语言客户端、K8s 服务发现、多数据中心路由
| 机制 | 核心目标 | 实现方式 | 适用场景 |
|---|---|---|---|
| 保护阈值 | 防雪崩 | 返回全量实例分流 | 大规模实例故障 |
| 权重路由 | 精细化流量调度 | 实例级权重分配 + 客户端负载均衡 | 性能优化、灰度发布、故障隔离 |
| 动态 DNS | 跨环境服务发现 | DNS 响应动态 IP 列表 + 权重 | 多语言接入、多集群路由 |
性能优化与场景问题
注册发现侧:
- 心跳参数 (
heartBeatInterval,heartBeatTimeout): 增大间隔和超时减少请求数(牺牲感知速度)。评估业务容忍度。 - UDP推送可靠性: 网络不稳定环境,可适当降低
pushReceiverTask的间隔(但增加Server压力),或监控UDP丢包率排查。 - 服务数 & 实例数爆炸: 合理划分Namespace/Group,避免单个Service下实例过多。优化应用逻辑,非必要不频繁getInstances。
nacos.naming.clean.clean-contaminated-service.interval/nacos.naming.clean.empty-service.interval: 控制清理无实例或脏数据服务(如因复制异常)的频率,减少内存占用。
配置中心侧:
configLongPollTimeout: 调整长轮询超时,平衡实时性和连接占用。集群压力大时可考虑略微加大(如40s)。- 批量监听: 尽可能在一个Listener监听多个
dataId(使用dataId=xxxx*通配监听),减少长轮询连接数。 - 压缩: 支持配置内容压缩传输,节省带宽。
- 客户端本地缓存 (
LocalConfigInfoProcessor): 保证即使短暂失联也能获取配置。
通用:
- JVM调优: 根据节点压力调整堆大小(
Xms,Xmx), G1 GC相关参数(MaxGCPauseMillis,InitiatingHeapOccupancyPercent)。 - 数据库性能: 持久化场景下DB是关键瓶颈。读写分离、分库分表、优化慢SQL。
- 集群规模: 合理评估节点数。CP模式建议3/5节点;AP模式节点过多同步开销增大。
distro.member-change-task.worker-count调整成员变化处理线程。
常见问题排查
- 服务注册/发现失败:
- 检查 Provider/Consumer 端配置的
nacos.addr是否正确可达。 - 查看 Nacos Server
/nacos/v1/ns/instance/list?serviceName=xxxAPI 返回是否包含目标实例。 ephemeral判断: 临时实例检查 Provider 日志看是否打印心跳成功/失败, 检查 Server端对应Service的内存注册表(控制台或API)。持久实例检查数据库config_info/his_config_info(配置历史) 或services/instances(服务注册) 表和Server的主动探活日志。- 检查网络:Nacos节点间端口(7848-CP Raft, 9848-AP Distro & 配置Notify, 8848-HTTP API)防火墙?Consumer订阅端口(UDP:8848+1000=9848)是否允许入站?
- 查看 Server 日志
logs/naming-raft.log(CP) /naming-distro.log(AP) /naming-server.log是否有异常。
- 检查 Provider/Consumer 端配置的
- 配置不更新:
- 检查 Client 是否确实
addListener并监听正确dataId+group。 - 抓包/Wireshark: 查看 Client 发起的
/v1/cs/configs/listener长轮询请求参数是否正确,Server 返回是304还是200。若返回200,Client是否立即发起GET拉取新内容。 - 检查控制台配置历史 (
config_info,his_config_info) 确认已发布成功。 - 查看 Server
config-server.log,有无[fixed-delay-task]相关日志异常。检查server.tomcat连接池(maxThreads,minSpareThreads,maxConnections)是否耗尽导致长轮询处理失败。 - 检查
pushEmptyProtection设置是否合理(导致不该返回空时返回空?)。
- 检查 Client 是否确实
- 集群脑裂/数据不一致:
- CP模式: 检查
naming-raft.log确认 Leader 唯一性 和 Leader/Follower 任期 (term) 是否一致。查看 Raft 选主日志 (选举成功/失败),网络是否隔离少数派。 - AP模式: 使用
/nacos/v1/ns/operator/distro/datum&datumsDistro元数据校验API检查各节点对同一Service的数据摘要(Digest)是否一致。观察naming-distro.log中数据同步 (sync,verify,retry) 日志是否频繁失败。distro.failed.task.retry.delay参数影响重试。根本解决:确保物理网络可靠,配置合理的节点探测超时
- CP模式: 检查
最佳实践
- 命名规范: 强制使用
Namespace(环境隔离:DEV/TEST/PROD),善用Group(应用/项目分组)。 - 实例划分: 大多数微服务场景使用临时实例 (
ephemeral=true),利用心跳自动上下线。基础设施服务(如数据库中间件)可用持久实例+主动探活。 - 配置管理:
- 敏感配置加密存储。
- 利用
shared-dataids或extension-configs(Nacos Spring Cloud) 共享公共配置。 - 大配置谨慎使用长轮监听,拆分小配置。
type明确指定 (yaml, properties, json)。
- 集群部署:
- AP模式(默认)用于服务发现和一般配置。
- 对强一致性配置使用CP模式 (
nacos.core.protocol.raft.data=true),部署3或5节点。 - 跨机房部署:AP模式使用 VIP + SLB 或部署 多个独立 AP 集群 + Sync组件(跨集群异步数据同步工具),避免脑裂。CP模式需确保多数派节点在同一可靠域内。
- 持久层分离: 生产环境务必配置外部 MySQL/PostgreSQL,避免使用内嵌 Derby。
- 客户端:
- 做好重试和降级 (如配置本地缓存失效后用默认值)。
- 监听器逻辑轻量级,避免阻塞

